Classic LLM Model
Bert
| title | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding |
|---|---|
| model | BERT |
| target | BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. |
| contribution | - Bidirectional Encoder Representations from Transformers. - using a “masked language model” (MLM) pre-training objective - also use a “next sentence prediction” task - pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. |
| background | 限制:标准语言模型是单向的,这限制了在预训练期间可以使用的体系结构的选择。例如OpenAI GPT, the authors use a left-toright architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer 现有的将预训练语言表征应用于下游任务的策略有两种: - feature-based ELMo (Peters et al., 2018a) - fine-tuning(bert proposed) OpenAI GPT (Radford et al., 2018) |
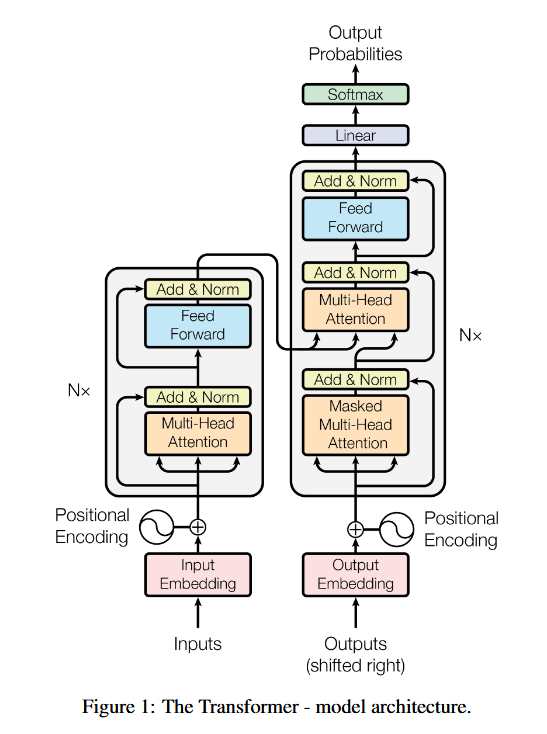
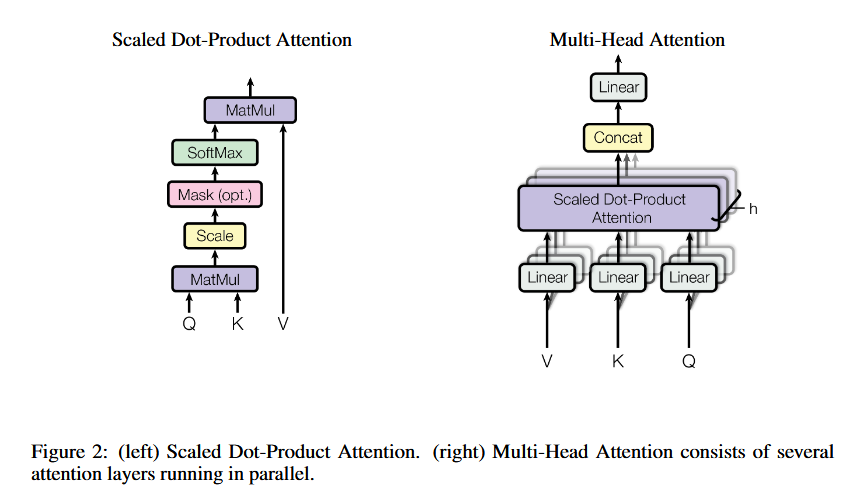
| method | There are two steps in our framework: 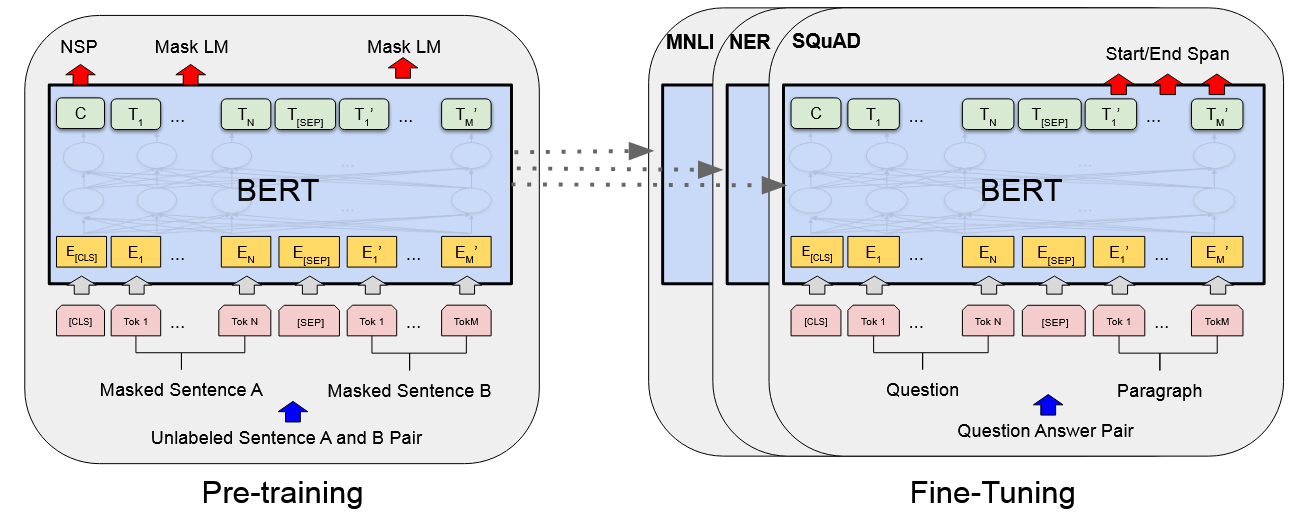 Model Architecture 1.Input/Output Representations able to unambiguously represent both a single sentence and a pair of sentences. We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary. 每个序列的第一个标记始终是一个特殊的分类标记( [ CLS ] )。区分单个句子与Pair:1.[SEP]token2.add a learned embedding to every token indicating whether it belongs to sentence A or sentence B. For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. 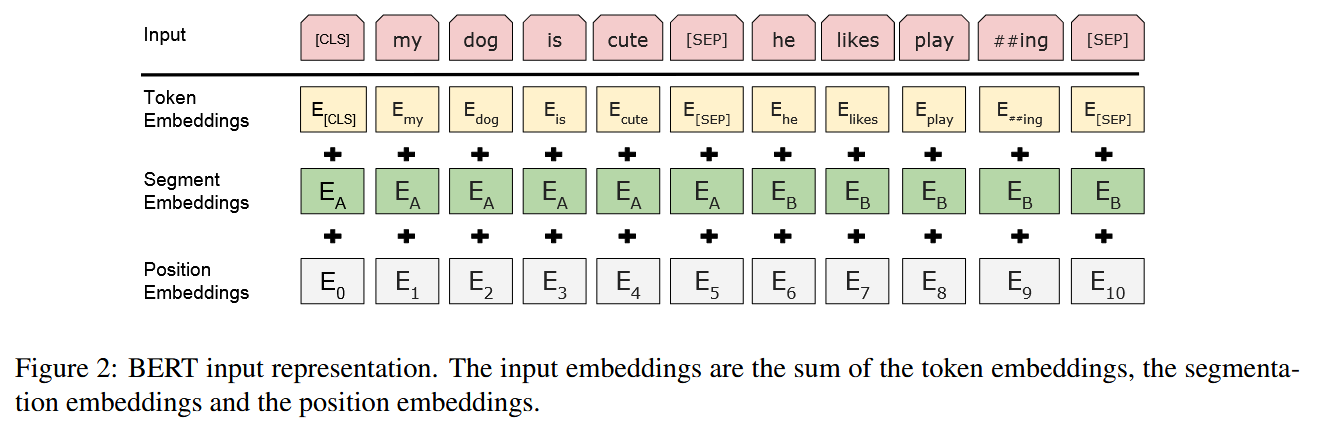 Pre-training BERT Task #1: Masked LM we mask 15% of all WordPiece tokens in each sequence at random problem:mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. solution:If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Task #2: Next Sentence Prediction (NSP) target:to train a model that understands sentence relationships method:当为每个预训练示例选择句子A和B时,50%的时间B是A之后的实际下一个句子(标记为IsNext),50%的时间是来自语料库的随机句子(标记NotNext)。 Pre-training data BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words). It is critical to use a document-level corpus rather than a shuffled sentence-level corpus loss following OpenAI GPT. The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood. Fine-tune BERT 对于text pair 以往的方法是independently encode text pairs before applying bidirectional cross attention,Bert整合了这两个过程:encoding a concatenated text pair with self-attention effectively includes bidirectional cross attention between two sentences. |
| conclusion | MLM does converge marginally slower than a leftto-right model (which predicts every token) difference 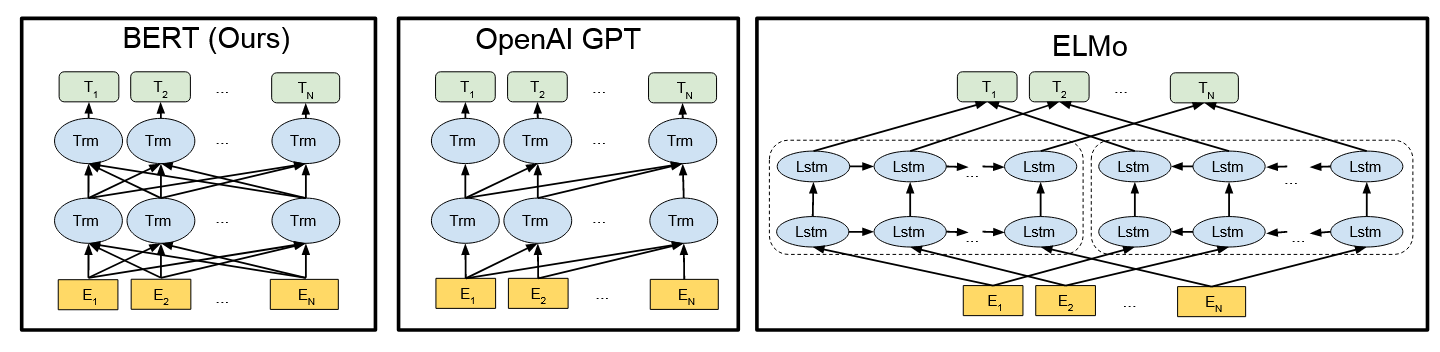 Longer sequences are disproportionately expensive because attention is quadratic(二次方) to the sequence length. To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps. Then, we train the rest 10% of the steps of sequence of 512 to learn the positional embeddings. |
| idea |
GPT
| title | Improving Language Understanding by Generative Pre-Training |
|---|---|
| model | Transformer model |
| target | Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks. |
| contribution | 1. 提出了一种通用的任务无关模型,通过生成预训练和微调,显著提高了多个自然语言理解任务的性能。 2. 在12个任务中有9个任务上超过了当前最先进的模型。 3. 证明了在多种任务上,预训练的Transformer模型在小数据集和大数据集上都能有效提升性能。 |
| background | |
| method | 提出了一种两阶段训练流程: 1. 预训练:在一个大规模未标注的文本语料库上使用语言建模目标进行预训练。模型采用Transformer架构,以便处理文本中的长距离依赖关系。 给定一个无监督的语料库U={u1,...,un},使用一个标准语言建模目标来最大化以下可能性: 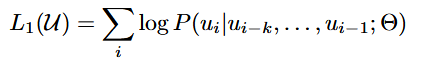 k是上下文窗口的大小,条件概率P使用神经网络建模。 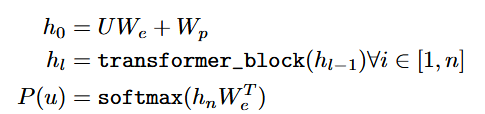 U = (u−k, . . . , u−1) is the context vector of tokens, n is the number of layers, We is the token embedding matrix, and Wp is the position embedding matrix. 2. 微调:在目标任务的标注数据上进行微调,使用特定任务的输入转换方式,以最小的架构改动实现有效的迁移学习。 输入:数据集C,其中每个实例由一系列输入标记x1,...,xm,以及标签y。 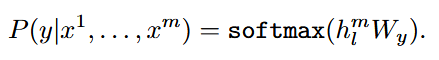 输入到预训练模型得到hl后激活得到 最大化目标: 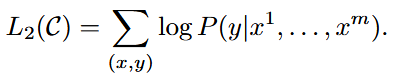 总体目标(结合了预训练时候的loss): 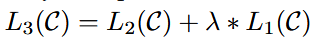 3.结构 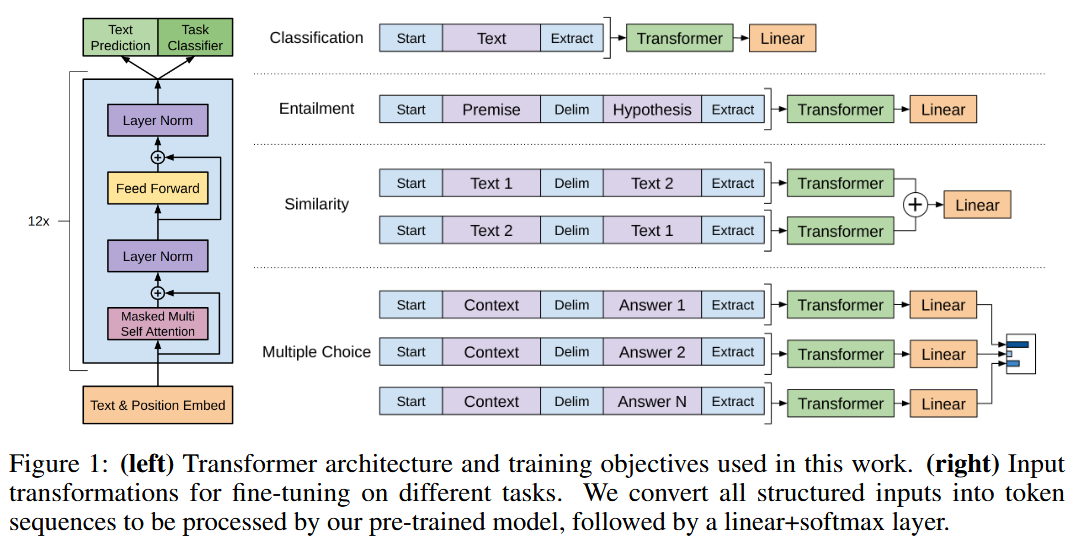 |
| conclusion | |
| idea |
GPT-2
| title | Language Models are Unsupervised Multitask Learners |
|---|---|
| model | Generative Pre-trained Transformer 2 (GPT-2) |
| target | 本文的主要目标是探讨大型语言模型在没有特定任务训练的情况下,能否通过零样本学习执行多种NLP任务。具体任务包括阅读理解、机器翻译、摘要生成和问答等。 |
| contribution | 1. 新数据集: 引入了WebText数据集,该数据集由超过800万篇来自Reddit高质量链接的网页文本组成,总计约40GB的文本数据。 2. 零样本学习: 展示了GPT-2模型在零样本设置下在多个NLP任务上的性能,证明了大规模预训练的有效性。 3. 多任务学习: 证明了一个单一模型能够在多个不同的任务中表现出色,而无需特定任务的监督训练。 |
| background | 传统的NLP方法依赖于监督学习和特定任务的数据集进行微调。而GPT-2的创新在于仅通过在大规模的无监督文本数据上进行训练,即可实现多任务学习,这减少了对大量标注数据的依赖。 |
| method | 1. 数据预处理: 使用WebText数据集进行训练,WebText包含从Reddit上获得至少3个karma的链接的所有外部链接所抓取的网页文本。 2. 模型训练: 训练任务是预测文本中的下一个词。GPT-2的训练目标是最大化预测下一个词的概率: 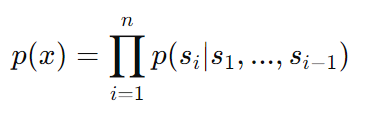 3. 评估: 在多个NLP任务上进行零样本测试,包括阅读理解(CoQA数据集)、机器翻译(WMT-14 Fr-En数据集)、摘要生成(CNN和Daily Mail数据集)和问答(Natural Questions数据集)。 |
| conclusion | GPT-2在零样本任务设置下表现出色,显示了其在多任务环境中的潜力。结果表明,通过大规模无监督预训练,模型能够泛化到多个任务,有时甚至达到最先进的水平。 1. 阅读理解: 在CoQA数据集上,GPT-2展示了强大的零样本问答能力。 2. 机器翻译: 在WMT-14 Fr-En数据集上的零样本翻译结果显示,GPT-2能够生成高质量的翻译。 3. 摘要生成: 在CNN和Daily Mail数据集上,GPT-2能够生成连贯且信息丰富的摘要。 4. 问答: 在Natural Questions数据集上,GPT-2展示了其理解和生成准确答案的能力。 |
| idea |
GPT-3
| title | Language Models are Few-Shot Learners | |
|---|---|---|
| model | GPT-3 | |
| target | 研究在不进行梯度更新或微调的情况下,GPT-3在少样本(Few-Shot)设置中的性能。 | |
| contribution | 1. 证明了通过扩展语言模型规模可以显著提高任务无关的少样本学习性能。 2. 在多个NLP数据集上,GPT-3在零样本、单样本和少样本设置中取得了显著的效果,有时甚至超过了现有的微调模型的表现。 |
|
| background | 近年来,NLP领域从学习特定任务的表示和设计特定任务的架构,转向使用任务无关的预训练和任务无关的架构。 | |
| method | 训练了一个具有1750亿参数的自回归语言模型(GPT-3),并在零样本、单样本和少样本设置下测试其性能。主要方法包括: 1. 零样本(Zero-Shot):仅使用自然语言描述任务,而不提供任何示例。 2. 单样本(One-Shot):提供一个任务示例。 3. 少样本(Few-Shot):提供多个任务示例(通常为10到100个示例)。  |
|
| conclusion | 1. GPT-3在零样本、单样本和少样本设置中均表现出色,证明了大规模语言模型在这些设置中的潜力。 2. GPT-3在语法、翻译、阅读理解、常识推理等任务上均表现出色,进一步验证了其广泛的应用潜力。 3. GPT-3的少样本学习能力显著,尤其在任务示例较少的情况下,展示了其强大的泛化能力。 |
|
| idea |
GPT-4
Hot Method
Attention
Transformer