Concept of SYS for LLM
Lifecycle for LLM SYS
- collection and preprocessing of data && choosing an appropriate model.
- training phase
- Model evaluation and fine-tuning
- serving stage
Challenge
- 模型的参数量不断增加从GPT-3(175B)到PanGu(1085B),导致需要的内存越来越多
- 集群中通信是瓶颈
most significant challenges are the high demands for memory and computational power.
Strategies
Overview
Model training
方向:Network, Computing, and Storage Optimization
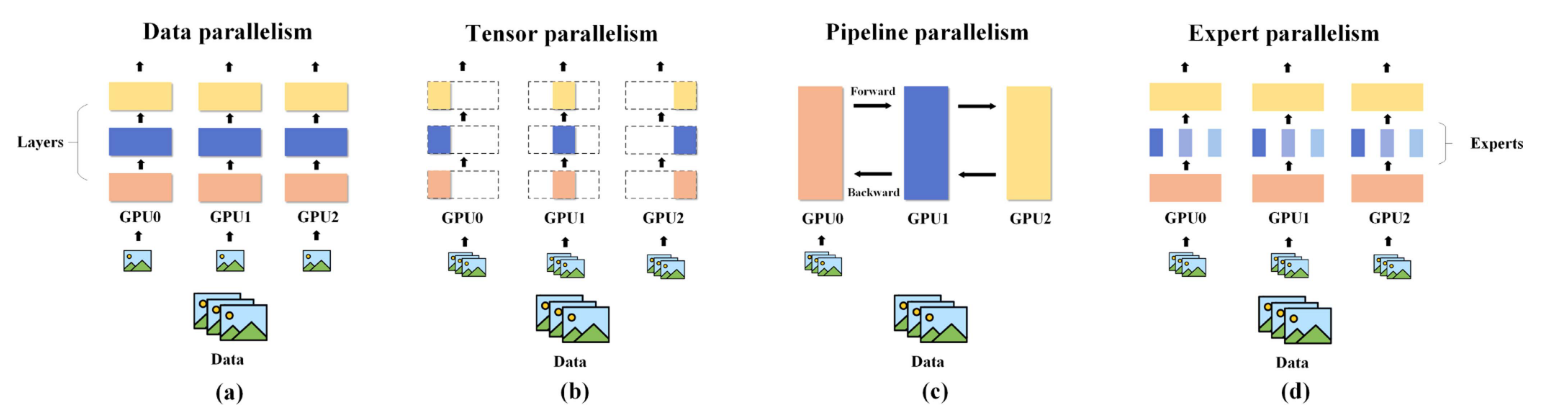
- parallel computing optimization
- data parallelism
- tensor parallelism
- pipeline parallelism
- expert parallelism
- hybrid parallelism
- memory optimization
- memory swap
- zero redundancy
- mixed precision training
- checkpoint and recomputation
- communication optimization
- communication optimization
Model service
- batch processing optimization
- sparse acceleration techniques
- resource scheduling
- GPU memory optimization
- multi-model inference
Model training
parallel computing optimization
| type | model | year | feature | code repo |
|---|---|---|---|---|
| data parallelism | FSDP | 2023 | ||
| DDP | 2020 | |||
| tensor parallelism | Megatron-LM | 1D | ||
| Optimus | 2D | |||
| Tesseract | 2.5D | |||
| 3-dimensional model parallelism | 3D | |||
| pipline parallelism | GPipe | |||
| DAPPLE | ||||
| PipeDream | ||||
| PipeDream-2BM | ||||
| Varuna | ||||
| Megatron-LM | ||||
| Chimera | ||||
| Hanayo | ||||
| MixPipe | ||||
| AvgPipe | ||||
| Dynapipe | ||||
| Bpipe | ||||
| Bamboo | ||||
| FTPipe | ||||
| expert parallelism | GShard | |||
| FastMoe | ||||
| FasterMoe | ||||
| DeepSpeed-Moe | ||||
| SmartMoe | ||||
| DeepSpeed-Ted | ||||
| Lina | ||||
| Janus | ||||
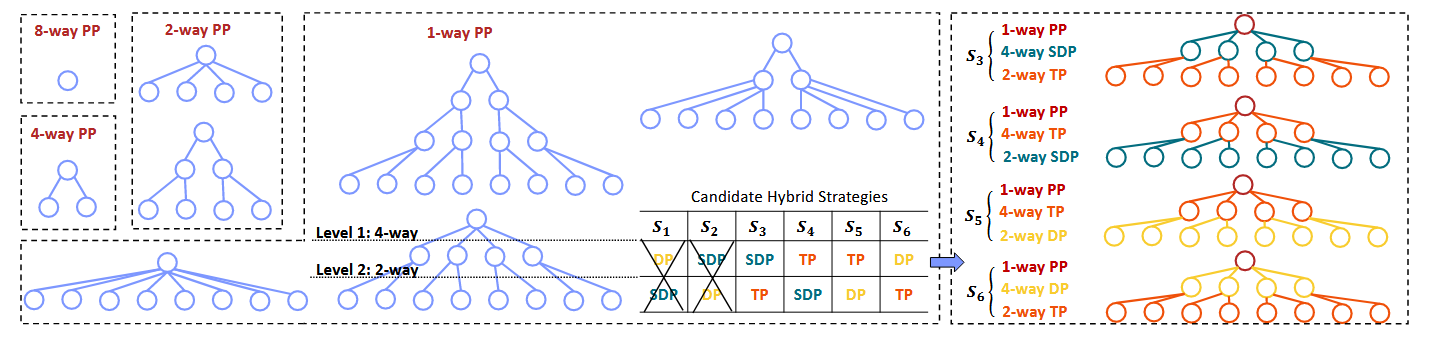
| hybrid parallelism | Alpa | |||
| Galvatron | ||||
data parallelism
数据并行的核心思想:大数据集分割成小块,然后在多个处理器或计算节点上同时进行处理。每个节点使用其模型副本进行前向和后向传播和梯度计算。因此需要梯度聚合和同步操作来更新全局模型参数。
DDP
在DDP中,在每个节点上存储整个模型的参数。
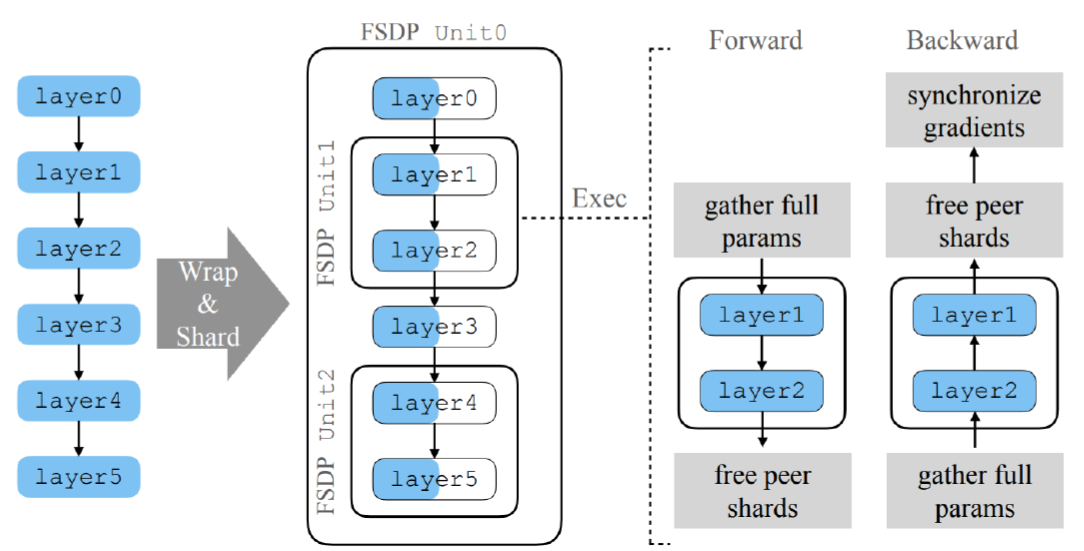
FSDP
它将模型参数分成更小的单元,在计算前通过通信恢复完整的模型参数,在计算后立即丢弃它们。
将模型参数 、 优化器状态和梯度进行分片
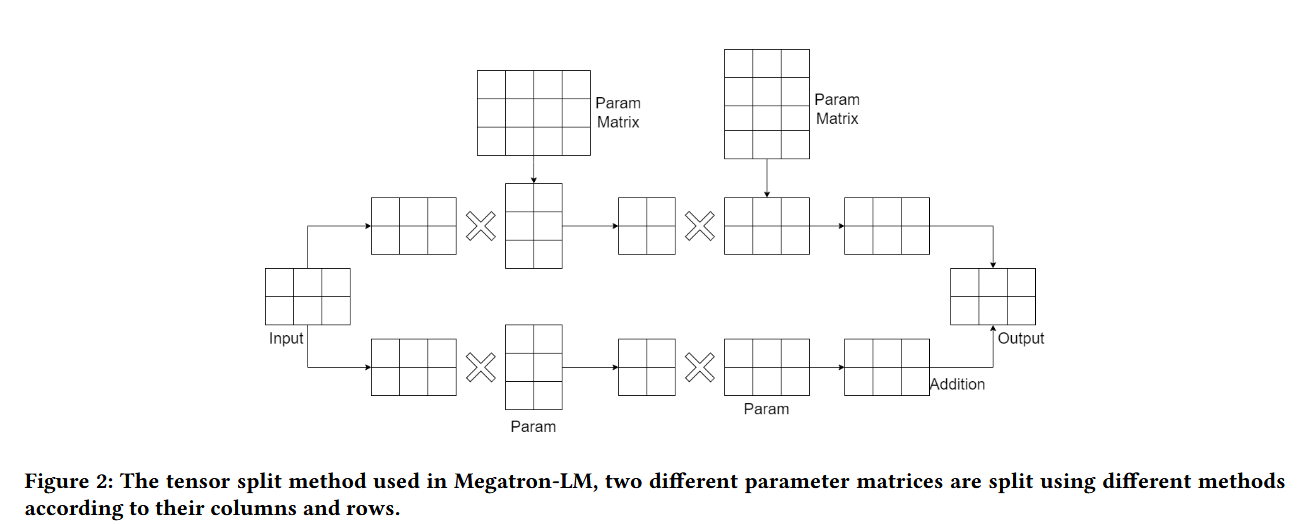
tensor parallelism
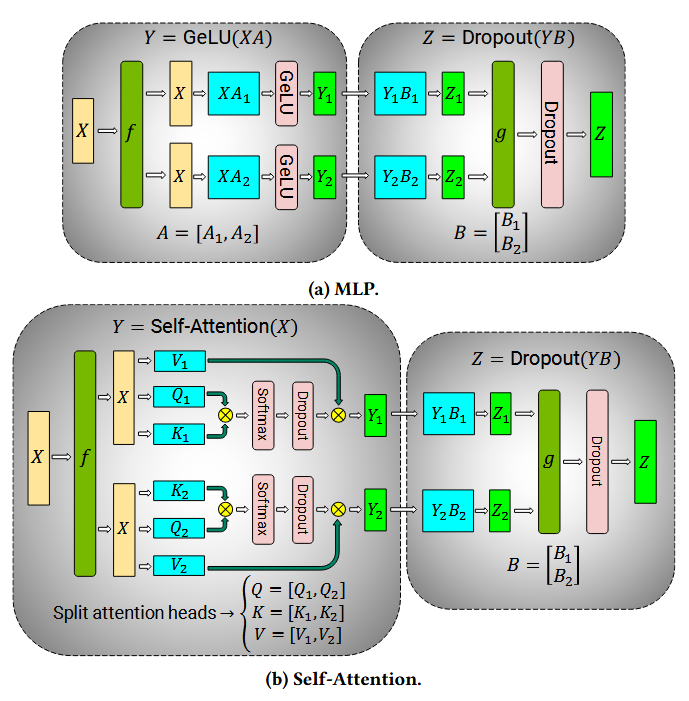
开发张量并行性是为了解决训练超过单个设备存储容量的基础模型的挑战。
计算两个密集矩阵
1D
在Transformer model模型中,1D张量平行的方法被有效地应用于多头注意的计算-多个处理单元同时计算不同的注意头。
2D
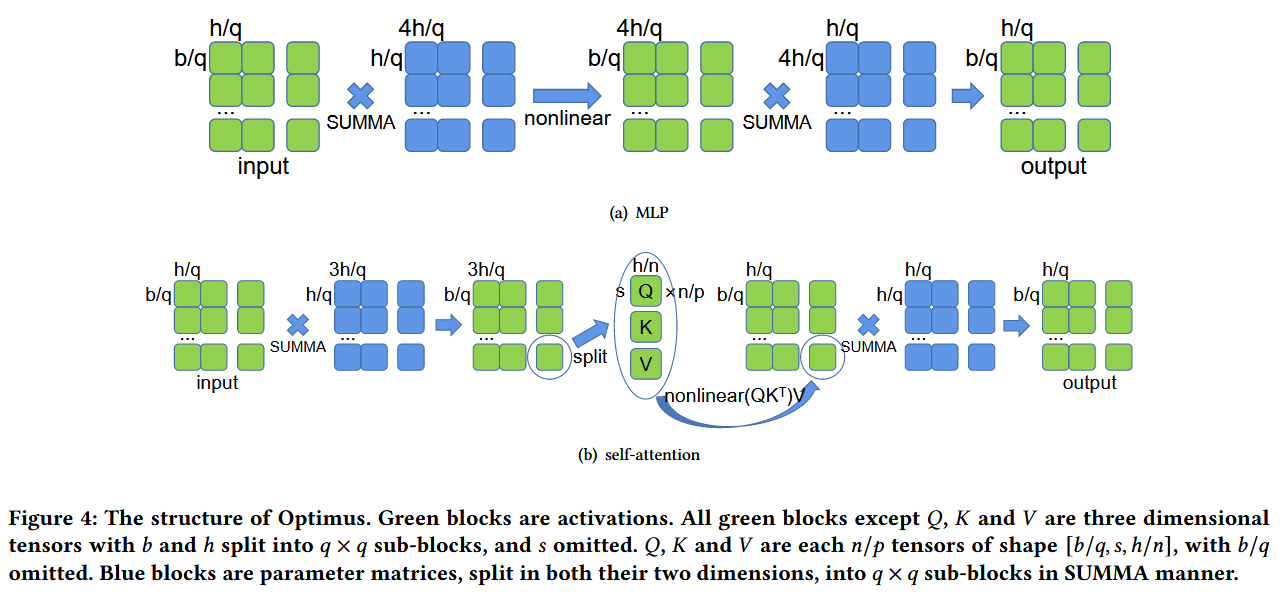
与1D张量并行相比,2D并行将计算负载分布在更多的处理单元上,显著提高了整体计算效率。
缺点:引入更高的通信开销
2.5D
3D
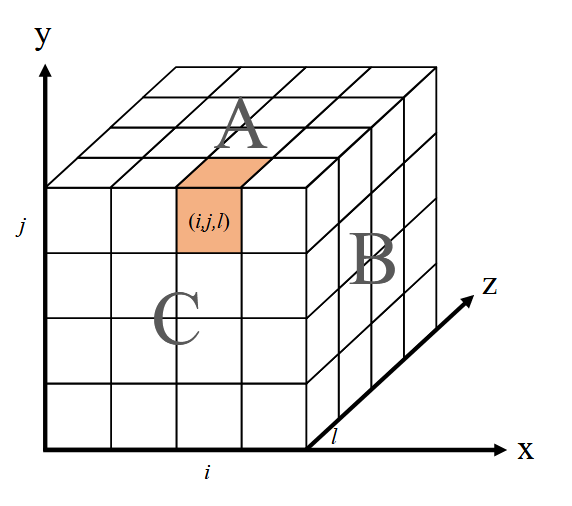
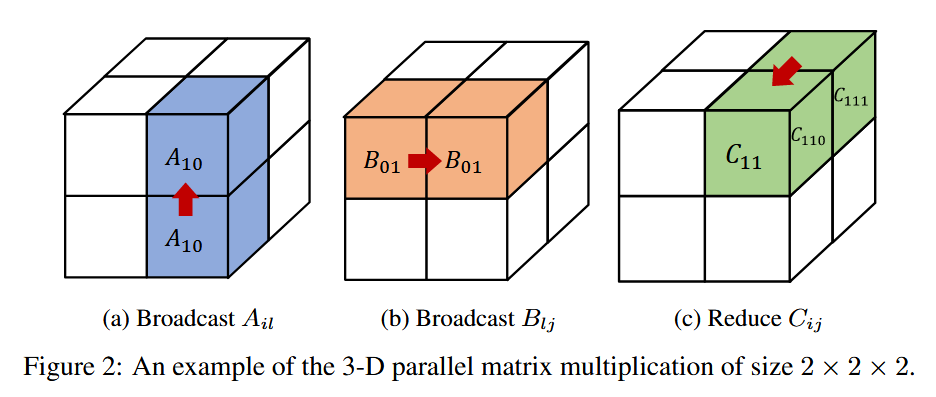
设A,B,C表示平面,x,y,z表示平面的方向,i,j,l表示沿方向的不同指数。彩色块(i,j,k)表示单个处理器的示例。还用A,B,C来表示乘法中涉及的矩阵,所以Aij,0≤i,j<p应该表示A的一个子矩阵。
考虑一个处理器2 × 2 × 2的cube,对于C=AB该乘法。将大小为(M,N)和(N,K)的A和B分成2 × 2个分区,如下所示,使得每个分区Ail和Blj的大小分别为(M/2,N/2)和(N/2,K/2),如下。
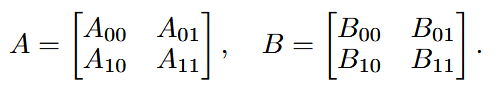
每个分区Ail存储在处理器(i,0,l)中,而Blj存储在(0,j,l)中。随后从(i,0,l)沿y方向广播每个Ail;沿着x方向广播每个Blj;随后在每个处理器(i,j,l)上计算Cijl=AilBlj。最后沿着z方向将Cijl简化为(i,j,0)。
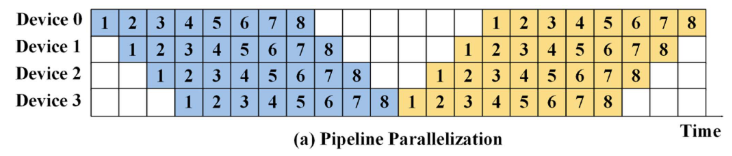
pipeline parallelism
- 典型问题:由于等待相关数据或处理结果而产生的空闲时间,通常称为气泡现象。
- 切分后的 stage 需满足硬件的资源限制(如显存)
- 计算时间最长的 stage 将成为流水线并行的瓶颈,因此要尽可能均匀切分
- Stage个数要尽可能少,以降低通信量
参数不一致的问题
异步更新参数会导致这个问题,影响模型收敛。
主流框架流水线实现是同步版本的
传统pipline

GPipe
提出 micro batch,但是流程和传统pipeline差不多
GPipe要求在开始反向传播之前等待每个微批处理完成正向传播。所以会导致很多气泡产生。下图展示了什么是气泡。
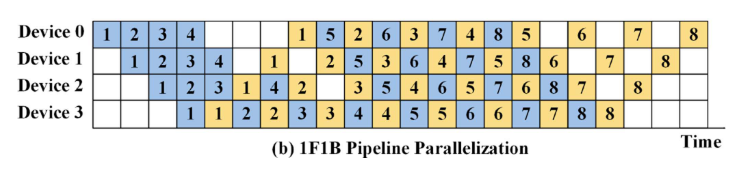
PipeDream
PipeDream使用1F1B算法,减少了气泡。
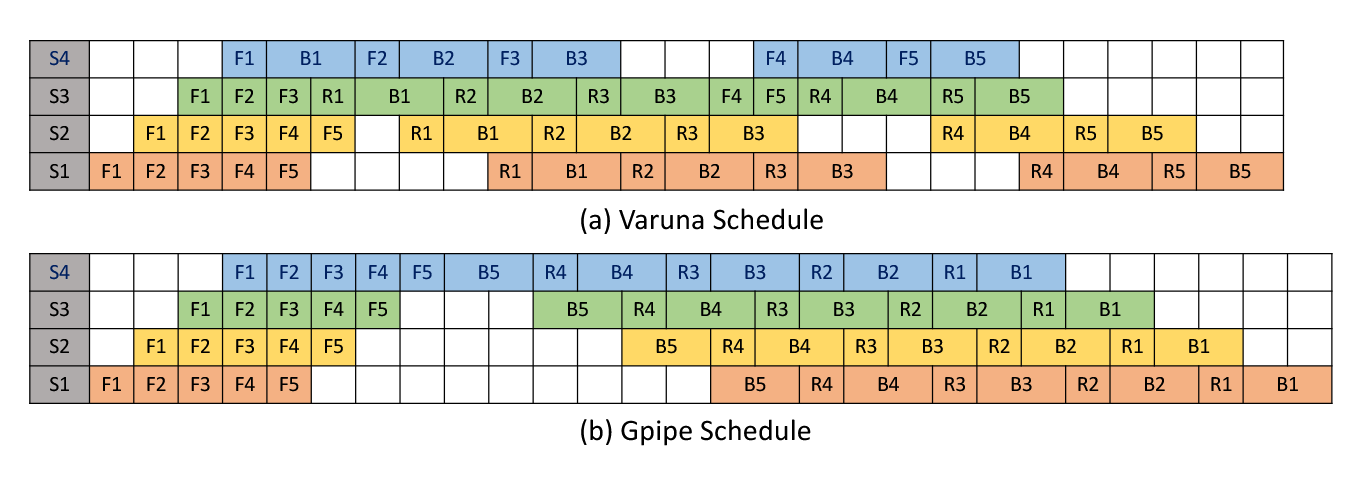
Varuna
Varuna改进了PipeDream,在向后传递的早期执行重新计算,有效地减少了气泡和内存使用。
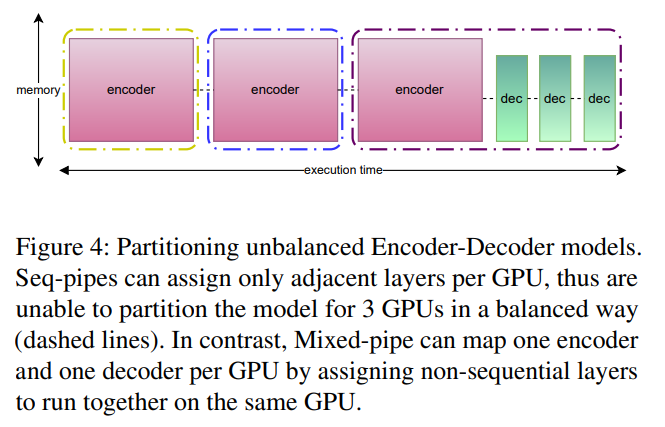
FTPIPE
- 和传统按模型层划分进行创新:一个模型可以覆盖几个层;
- 启发式算法分配块,通信量高的合并为一个块
Mobius
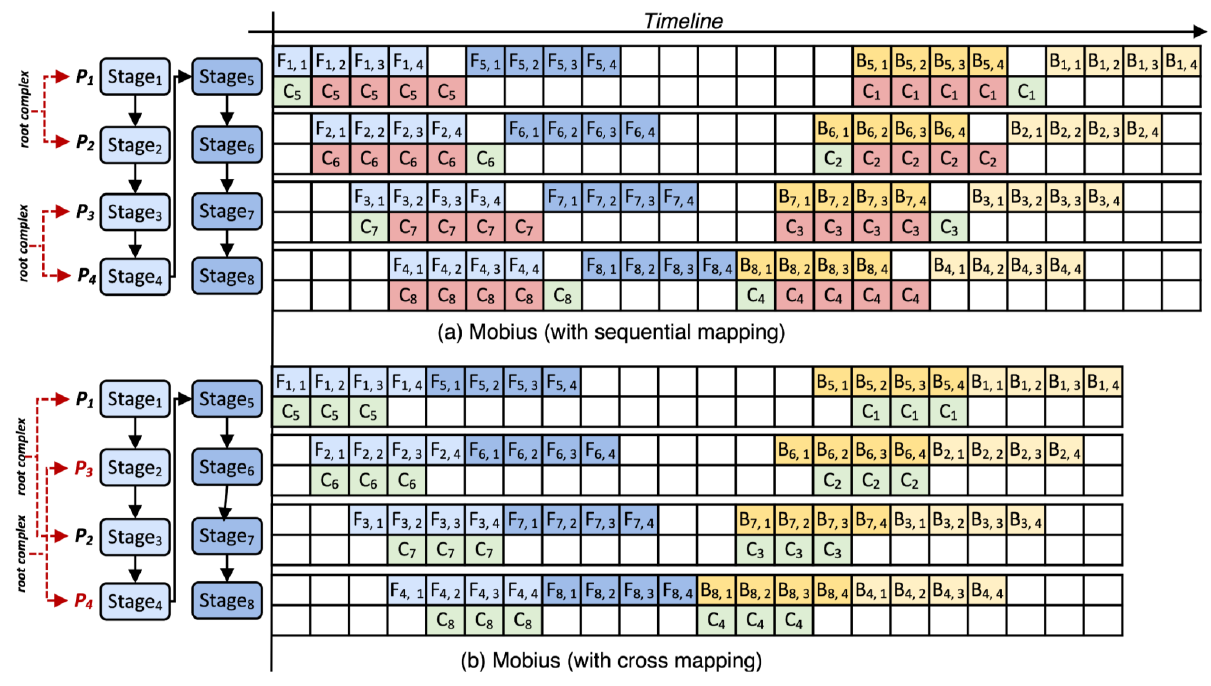
交叉放置 stage 到不同的CPU 来减少通信争用
Chimera
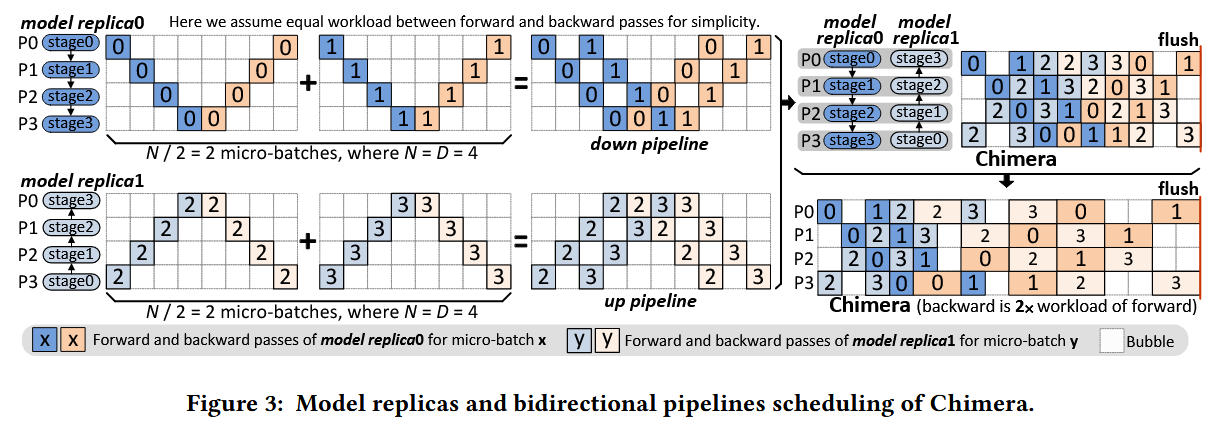
在一个GPU部署模型的多个 stage ,实现双向流水线 ,进一步 减少气泡 和缩短计算时间,下图的
expert parallelism
核心思想:稀疏化的方法,无需让整个模型来处理所有的输入。通过对神经网络进行划分,它让神经网络也“专业对口”,不同的子模型只处理固定类型的任务或数据。
MoE架构中,输入样本首先通过GateNet进行一个多分类的判别过程,确定最合适的专家模型。然后,选定的专家模型接管输入样本的处理,输出最终的预测结果。
这部分还没有太看懂,先放着
GShard
GShard基于Transformer model的基础模型中首次引入了MoE结构
通过条件计算来扩展Transformer model,方法是用稀疏激活的专家位置混合(MoE)层替换每隔一个FF层,在编码器和解码器中都使用top-2门控的变体。
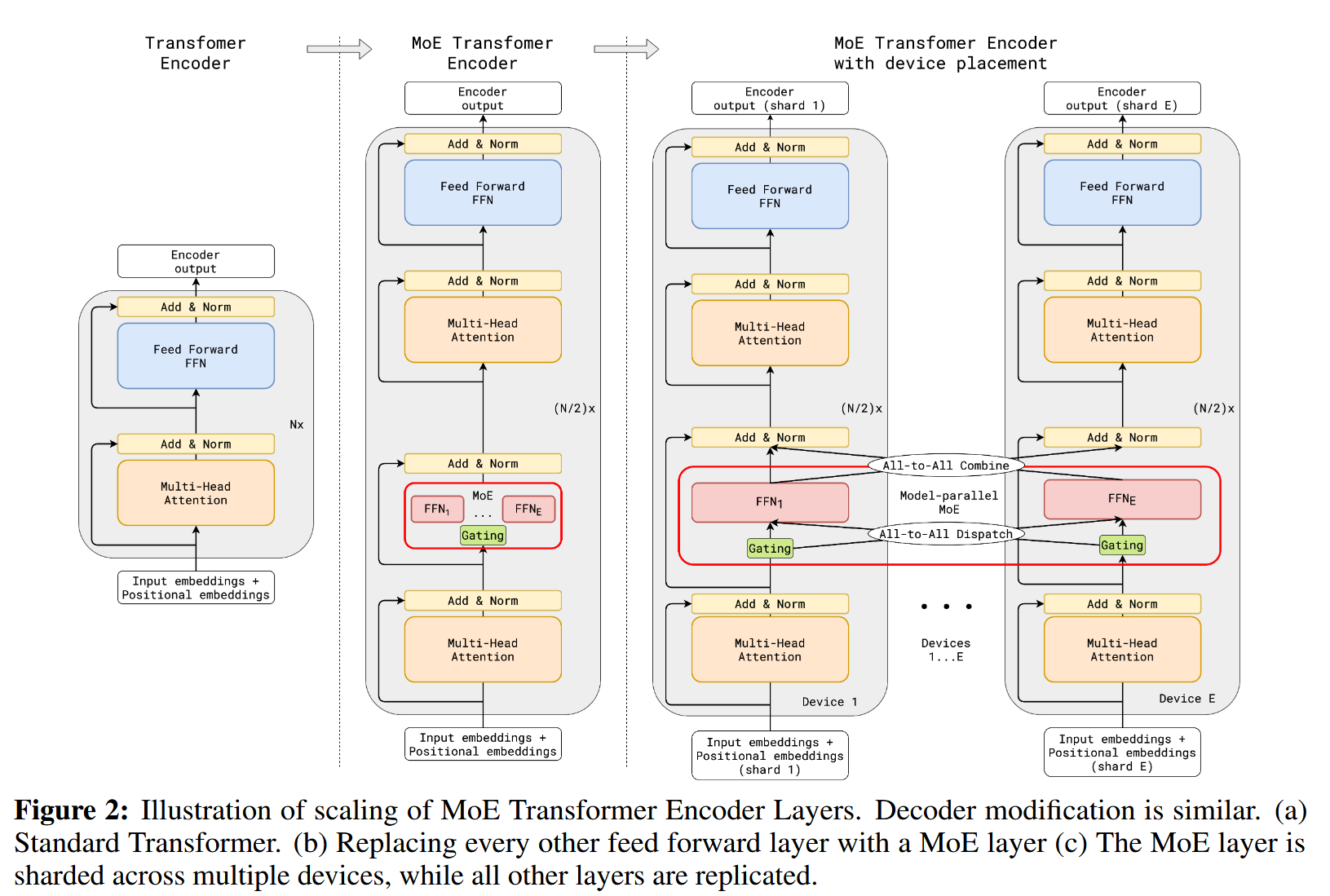
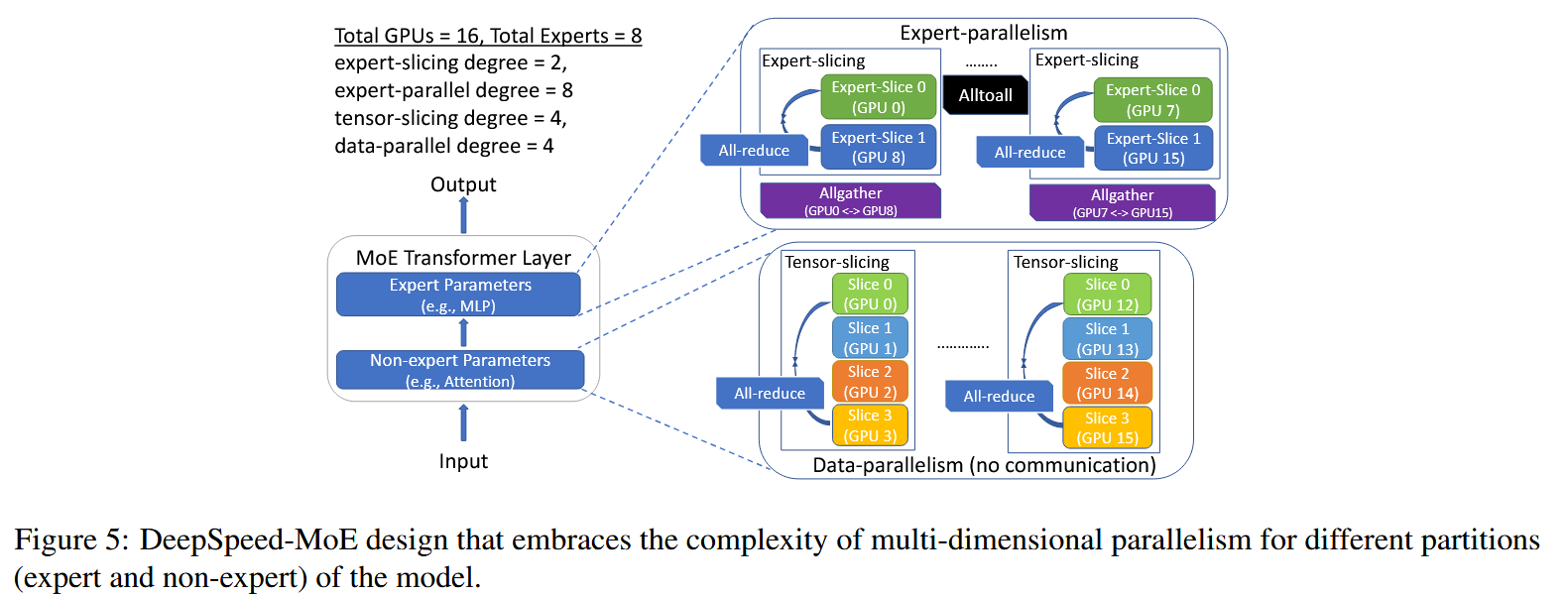
Deepspeed
(有点复杂)
FastMoe
| FasterMoe |
| DeepSpeed-Moe |
| SmartMoe |
| DeepSpeed-Ted |
| Lina |
| Janus |
hybrid parallelism
背景:单一的并行策略往往无法满足实际深度学习模型训练中不断增长的计算需求和复杂性。
核心:能够根据任务的具体要求和可用的硬件资源做出定制的策略选择
Alpha
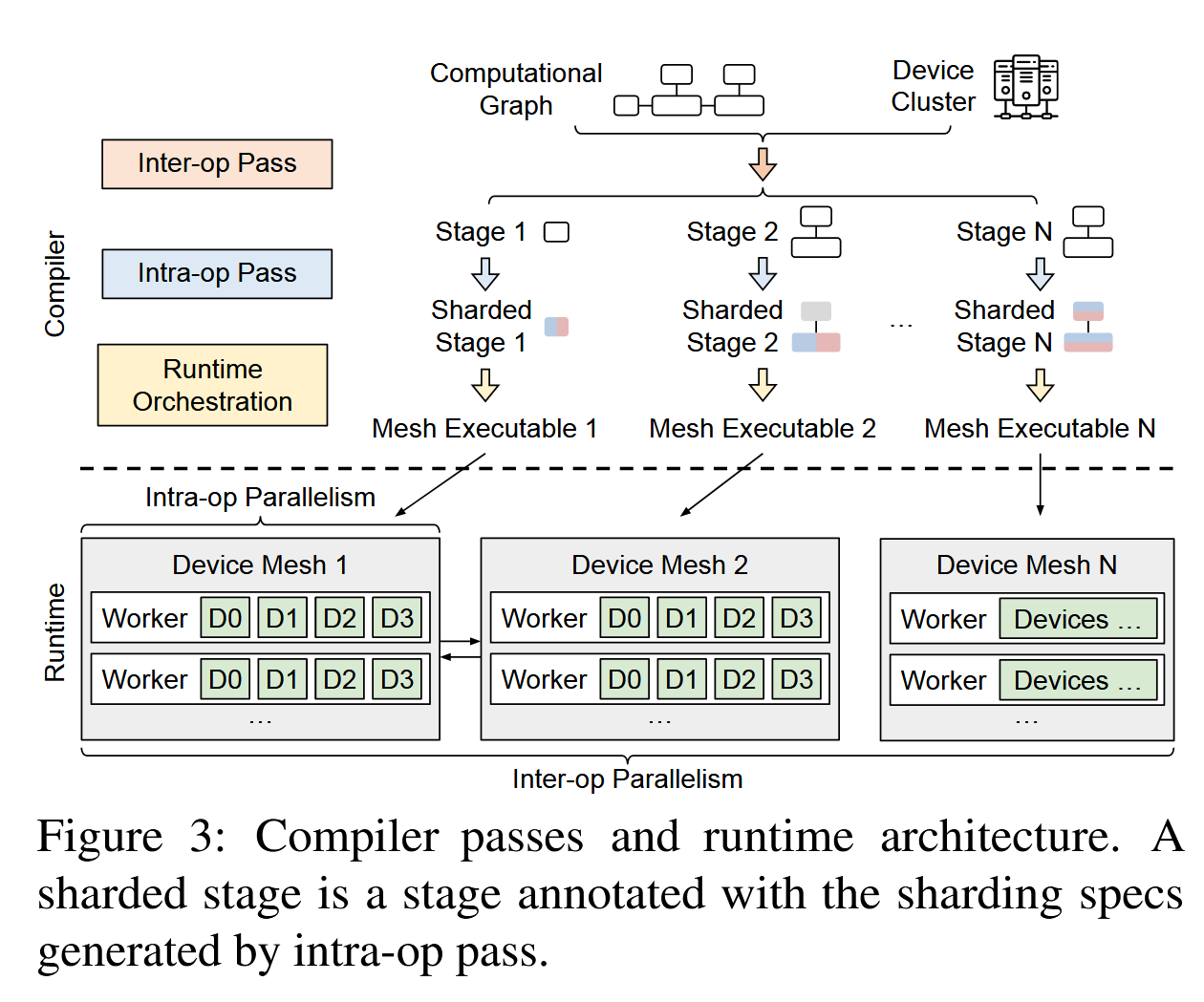
将所有并行化策略集成到一个框架中,建立了一个自动生成最佳并行化策略的编译器。
两阶段分层:输入模型的计算图和集群的信息,首先将模型划分为若干个stage(pipeline),然后将每个stage切分为若干个 shard Tensor (tensor paral;data paral)。
划分stage:动态规划,最小化延时
划分shard tensor:整数规划,最小化计算与通信
Galvatron
剪枝操作,有点复杂